Why Version Control Exists: Before Git (1/3)
Subject: Re: build failing on server
Hi all,
Does anyone still have parser.c from last Thursday’s build?
I’m looking for the version prior to the logging changes. The build was stable at that point, and I suspect a regression after that.
If someone has it, please send the file.
Thanks,
a tired developer, 1992
That might have felt like a strange mail, but it was routine to the developers who lived through it
This was exactly the kind of friction that forced better tools into existence.
To understand why, we need to go back to a time when computers were still strange boxes that took their time “thinking”
Mail and Pendrive Era

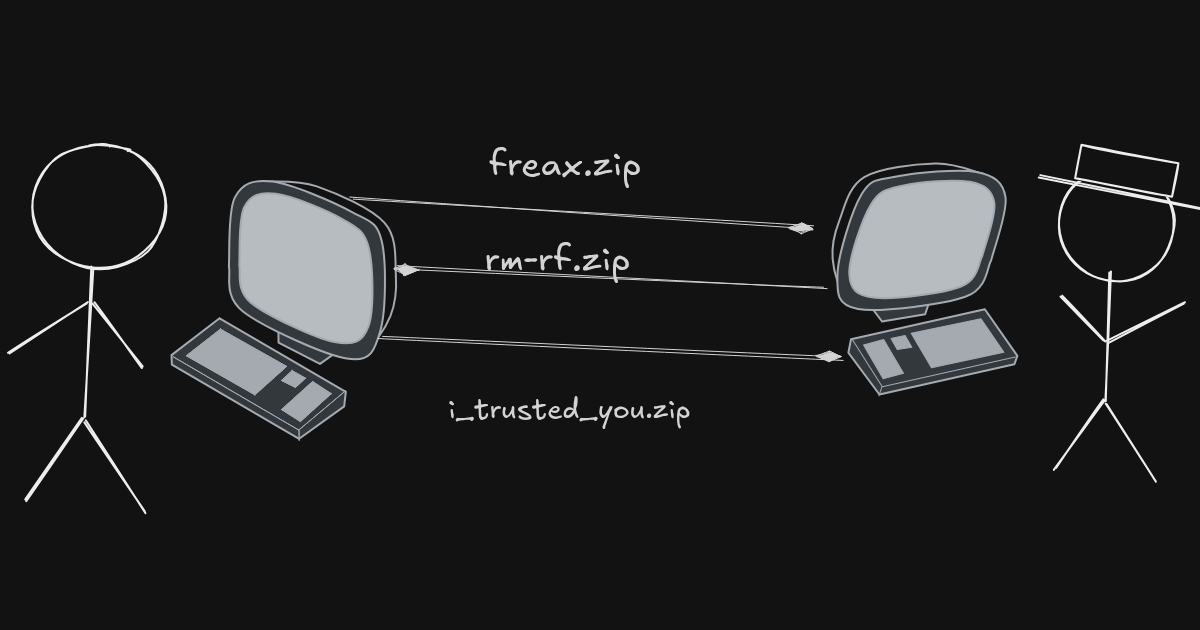
Picture yourself, a young enthusiastic nerd in the 90s, sitting in front of your IBM PC clone running Minix. You and you friends are working on a fun project Freax
You know a guy who really knows his way around MASM so you drop a mail asking for help. He is onboard, you send him the code zip over mail and so the collaboration begins. Life goes on, your project is being talked about on IRC Channels and before anyone knows, tens of people are sending over their patches for this revolutionary new software
- You send
latest.zipto Dennis- Dennis reverts with an updated
parser.c- You manually pick and choose changes to keep, compile and run
- Guido is joining as a new contributor so Tim sends him
project.zip- You notify Tim about the updated parser, send him the
latest_really.zip- Here comes Bjarne wholly persuaded by Richard’s take on Libre Licensing and now we suddenly have
I_Love_Libre.zip
The issue is glaringly obvious.
THERE IS NO ORGANIZATION IN THE CODEBASE
Everyone has their own version of the truth. This is where early version control systems enter the picture.
Early Version Control Systems
Centralized VCS
- There is one central repository that everyone depends on (Source of Truth)
- You need to be connected to the server in order to make changes
- Each developer gets a working copy, not the full repository
- History is on central server
CVS
There is chatter about version control and there exists this software named CVS. You start using CVS with the help of your friend Ari
Now you have one server hosting the Project. Workflow looks something like this:
- Copy project from Server
1
cvs checkout project
Everyone has a local copy on your computer BUT meaningful actions still depend on the server You start modifying
main.con your local FS.There is no lock on files. Someone changed
main.cwhile you were working on it and committed before you? Well, tough luck - Update before committing
1
cvs update
This the stage where you pull changes from the server (yea change first, pull later)
Remember your
main.cchanges? They are currently in conflict with latest at server. You have to manually pick and choose changes to keep - Commit
1
cvs commit
After resolving conflicts, you commit your changes. Each file is committed independently - if something fails midway, you can end up with a partially applied change.
SVN
Someone on the IRC suggested Subversion so you decides to give it a try!
The workflow stayed similar
- Copy project from Server
1
svn checkout project
- Lock file if you want
1
svn lock main.c -m "Editing civilization"
You can edit the file locally. Others can still modify it locally, but they cannot commit changes while the lock is held.
- Commit
1
svn commit main.c -m "Update civilization"
Now you can commit changes atomically. Some improvement finally!
- Unlock the File
1
svn unlock main.c
The file is now available for someone else
Issues with Centralized VCS
- The server is a Single Point of Failure
- History is stored on the server making your working copy incomplete
- Branching while Technically Possible, is expensive
Distributed VCS
- No central server (No source of Truth)
- Every local copy is a Full Repository including history and branches
- Branches are Lightweight and Cheap making it part of workflow
BitKeeper
Freax has become widespread. Hundreds of contributors and Thousands of lines of code
CVS and SVN don’t scale to this level so you decided to go Distributed
Bitkeeper is a famous DVCS but it is proprietary. Alas! the project needs it so you compromise and start using it
The catch is the license. Contributors are explicitly forbidden from reverse-engineering BitKeeper, and violating this condition means losing access entirely.
Latest workflow is something like this
- Clone the Repository
1 2
bk clone bk://freax.bkbits.net/freax-2.5 freax cd freaxYou have a full repo copy with all history and branches
Make Changes Locally
Edit the files you want to change. No need to manually Lock and Unlock files. No connection to the server
- Commit Changes
1
bk commit
Commits were local and Atomic
- Pull Changes
1
bk pull
Pull changes from others. This might create conflict
Resolve Conflicts
BitKeeper knew which changes conflicted so conflict resolution was easier
Merges had explicit Record making it traceable
- Push Changes
1
bk push
Your changes are now available to others. Contributors choose if they want to pull changes or not
A new beginning
Freax now depends on a proprietary tool, governed by a license that could be revoked at any time.
For a project built on open collaboration, that dependency could not last…